×
 クリックまたは Esc で閉じる
クリックまたは Esc で閉じる
クリックまたは Esc で閉じる
統一プロセスフロー
クリックで拡大表示
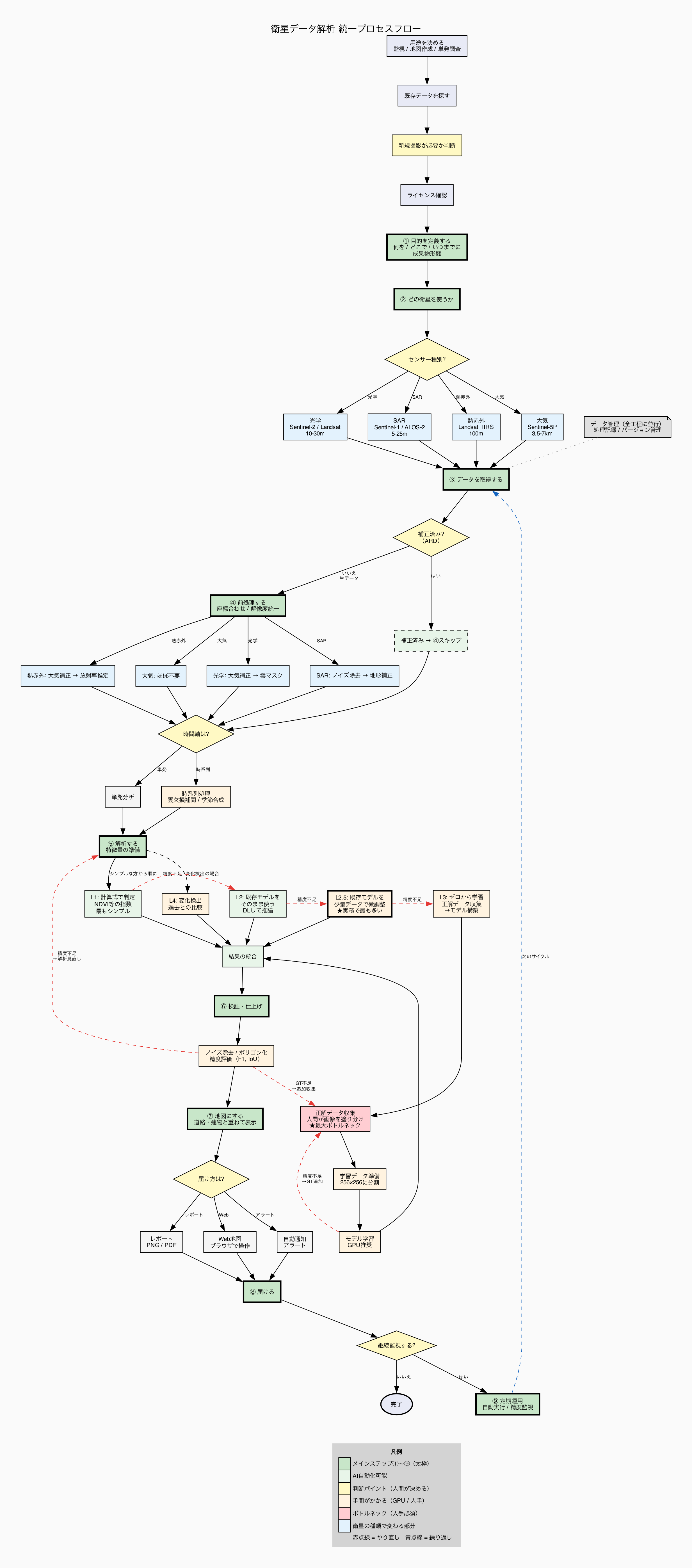
衛星データ解析 — 作業手順書
v7 — 2026-03-16 | Day 5実績反映 + 軌道選択・AOIクリップ・GTソース追加
AI AIエージェントが実行
人間 人間が判断
待ち 転送・計算の待ち時間
環境 ハードウェア依存
数分 数時間 数日〜
全工程サマリー — 何にどれだけ時間がかかるか
工数には4つの種類がある。AIエージェントが消せるのは「コードを書く時間」だけ。データの転送と計算は物理制約で変わらない。
| ステップ | コードを書く AI |
データ転送 待ち |
計算処理 環境 |
人間の判断 人間 |
|---|---|---|---|---|
| 前段階 | — | — | — | 数時間 |
| ① 目的定義 | — | — | — | 数日 |
| ② センサー選定 | 5分 | — | — | 数時間 |
| ③ データ取得 | 10分 | 数時間〜1日 50-200GB | — | 10分 |
| ④ 前処理 | 30分 | — | 数時間 CPU:半日 / Cloud:1-2h | 30分 |
| ⑤ 解析(L1/L2) | 10分 | — | 数分 | 10分 |
| ⑤ 解析(L2.5) | 30分 | — | GPU: 1-3h | 数時間 |
| ⑤ GT収集 | — | — | — | 数週間〜数ヶ月 ★ |
| ⑤ 解析(L3学習) | 30分 | — | CPU:数日 / GPU:数時間 | 数時間 |
| ⑥ 検証・仕上げ | 20分 | — | 数分 | 数時間 |
| ⑦ 地図化 | 15分 | — | 数分 | 30分 |
| ⑧ 配信 | 30分 | — | 数分 | 数時間 |
本当の時間泥棒は3つ:
1. ③のデータダウンロード(数十〜数百GB、回線速度次第)
2. ⑤のGT収集(人間が画像を見て塗る、数週間〜数ヶ月)
3. ⑤のGPU学習(ハードウェア次第、CPU数日 vs GPU数時間)
コードを書く時間は全部合わせても3時間程度。AIエージェントが消すのはここだけ。
1. ③のデータダウンロード(数十〜数百GB、回線速度次第)
2. ⑤のGT収集(人間が画像を見て塗る、数週間〜数ヶ月)
3. ⑤のGPU学習(ハードウェア次第、CPU数日 vs GPU数時間)
コードを書く時間は全部合わせても3時間程度。AIエージェントが消すのはここだけ。
前段階 — 始める前に確認すること
衛星データで何かを調べようと思ったとき、いきなりデータを取りに行くのではなく、「そもそもデータが存在するか」「使っていいか」を確認する。これを飛ばすと途中で詰まる。
データの存在確認 未体験
- 1STAC APIに対象地域(緯度経度の矩形)と期間を指定して検索クエリを送る AI コード15行・5分
- 2返ってきた画像一覧から、雲被覆率20%以下のシーンだけに絞り込む AI コード内で自動
- 3月別のヒット数を棒グラフにする(「何月に使える画像が何枚あるか」の可視化) AI コード10行
- 4グラフを見て「年間で十分な枚数が確保できるか」を判断する 人間 5分
ボルネオ島 100km四方 × 2024年をSTACで検索 → 雲被覆率20%以下は年間30枚(月平均2.5枚)→ 乾季(6-9月)は月5枚、雨季(11-2月)は月0-1枚 → 「雨季はSAR併用が必要」と判明
ライセンス確認 未体験
- 1使いたいデータソースの利用規約ページを開く 人間 10分
- 2「商用利用可否」「再配布可否」「クレジット要件」の3点を確認する 人間
Google Earth Engine = 非商用のみ。Copernicus = 商用可(クレジット要)。Planet/Maxar = 有料ライセンス契約が必要。
① 目的を定義する
「何を知りたいか」を決めることで、衛星・手法・成果物の形がすべて決まる。ここが曖昧だと全工程が迷走する。
要件の4項目を埋める 部分的
- 1何を: 検出(洪水が起きたか)/ 分類(森林か農地か)/ 測定(面積は何ha)/ 監視(減り続けていないか)→ どれかを決める 人間
- 2どこで: 対象地域を地図上で矩形 or ポリゴンで指定する。GeoJSONで定義 人間
- 3どのくらいの細かさで: 10m(無料衛星で見える森林区画レベル)で十分か、1m未満(商用衛星で見える個々の木)が必要か 人間
- 4成果物の形: PDFレポート / ブラウザ地図 / API / 自動通知のどれか → ⑧の工数が決まる 人間
この4つは人間にしか決められない。AIは選択肢の提示と比較表の作成で補助できるが、決定は事業判断。
② どの衛星を使うか選ぶ
衛星にはそれぞれ「得意な見方」がある。目的に合った衛星を選ぶことで後の全工程が決まる。
候補の比較と選定 体験済
- 1AIに「目的は○○、地域は○○、予算は○○」と伝える 人間 5分
- 2AIが候補センサーの比較表を自動生成(解像度・頻度・コスト・得意分野) AI 3分
- 3表を見て使うセンサーを決める 人間 10分
「森林減少を月次で監視したい、熱帯、予算なし」→ AI: 「Sentinel-2(光学・無料・10m・5日周期)推奨。ただし雲が多い地域ならSentinel-1(SAR)併用を検討」
③ データを取得する
使う衛星が決まったら、実際に画像データをダウンロードする。コードは短いが、ダウンロード自体に数時間〜1日かかるのがこのステップの実態。
STAC APIでデータ検索・取得 体験済
- 1pystac-client で Copernicus STAC に接続。対象AOI(矩形)と期間を指定して検索 AI コード15行・5分
- 2雲被覆率でフィルタし、使える画像の一覧を取得 AI コード内で自動
- 3軌道(Orbit)パスを確認する。同じ地域でも軌道が違うとカバー率が全く異なる。
sat:relative_orbitでフィルタし、対象地域を最も広くカバーする軌道を選定 AI コード5行 - 4サムネイル画像(TCI=True Colorの低解像度版)を5-10枚表示して目視確認。「これは使える、これは雲がかかっている」を確認 AIコード生成 → 人間が目視 10分
- 5必要なバンドだけを指定してダウンロード。全バンド不要なら容量を大幅に減らせる(例: NDVI用ならB04+B08の2バンドだけ → 1/6のサイズ) AI コード20行
- 6ダウンロード実行。ここが時間かかる 待ち
データ量の目安
100km四方 × 12ヶ月 × 全バンド = 50-100GB100km四方 × 12ヶ月 × 2バンド = 8-15GB
10km四方 × 12ヶ月 × 全バンド = 0.5-1GB
ダウンロード時間の目安
100GB @ 100Mbps = 約2-3時間100GB @ 10Mbps = 約1日
15GB @ 100Mbps = 約20分
COG利用時 = 必要部分だけ、数分〜
軌道パス選択を忘れると致命的。Day5で体験: R046軌道ではカバー率0.8%、R089軌道では82.5%。同じ地域・同じ日付でも軌道が違うだけで使い物にならない。STAC検索後に必ず
sat:relative_orbit でグループ化し、カバー率が最大の軌道を選ぶこと。コードは15分で書ける。しかしダウンロードに数時間〜1日かかる。夜間に走らせるか、COGストリーミング(全量DLせず必要タイルだけ取得)を使うかの判断が必要。
COGストリーミング(全量DLしない方法) 体験済
- 1rioxarray/stackstac で COG の URL を指定。HTTP Range Request で必要な範囲だけ読む AI コード20行
- 2メモリ上で処理。ディスクに保存しない(= ダウンロード不要) 待ち 範囲次第で数秒〜数分
全量DL vs COGストリーミングの判断: 同じデータに何度もアクセスするなら全量DL。一回だけ使うならCOG。
分岐: データはそのまま使える状態か?(ARD判断)
取得したデータがすでに補正済み(ARD)なら④の大部分をスキップできる。Day1-4で使ったデータはほぼARDだった。
ARD判定 体験済
- 1取得したデータのプロダクトレベルを確認する。ファイル名やメタデータに「L2A」とあればARD AI 自動判定
- 2L2A(Sentinel-2)/ Level-2(Landsat)→ 大気補正・幾何補正・雲マスク済み。④の多くをスキップ
- 3L1C(生データ)/ 商用衛星の生画像 → ④をフル実施
CopernicusやGEEからダウンロードするデータはほぼL2A(ARD)。生データからの前処理が必要になるのは、商用衛星データや特殊な用途の場合。
④ データを使える状態にする(前処理)
衛星の生データには大気の影響やノイズが含まれている。これを取り除く。ARDデータを使う場合、この工程の大部分はスキップできる。コードは短いが、大量データの計算に数時間〜半日かかる。
雲マスク適用 体験済
- 1L2AデータにはSCLバンド(Scene Classification Layer)が付属している。これを読み込む AI コード5行
- 2SCL値が「雲(8,9)」「雲影(3)」「水蒸気(10)」のピクセルをマスク(NaNに置換) AI コード3行
- 3マスク後の画像を目視確認。雲の取り残しがないか 人間 5分
時系列の雲欠損を埋める(ギャップフィル) 未体験
- 112ヶ月分の画像をxarrayのデータキューブとしてスタック(時間×緯度×経度×バンド) AI コード20行
- 2各ピクセルの時系列でNaN(雲除外部分)を時間方向に線形補間する AI コード10行
- 3計算実行。データ量次第で時間がかかる 待ち
計算時間の目安
10km四方×12ヶ月 = 数分100km四方×12ヶ月 = 数時間(CPU)
100km四方×12ヶ月 = 30分-1時間(32コア Cloud)
工数の内訳
コード: 30行・15分 AI計算待ち: 数分〜数時間 待ち
結果確認: 10分 人間
季節合成(3ヶ月分→1枚の代表画像にまとめる) 体験済
- 13ヶ月分の画像をグループ化し、各ピクセルで中央値を計算する(外れ値=雲の残りが消える) AI コード10行
- 24季節分(1-3月, 4-6月, 7-9月, 10-12月)の合成画像を生成 AI
- 3合成画像を並べて表示し、季節変化が捉えられているか目視確認 人間 5分
解像度不整合のハンドリング 体験済
- 1使用するバンドの解像度を確認する。例: Sentinel-2のB04/B08=10m、SCL=20m、B05-B07=20m AI 確認のみ
- 2低解像度バンドをリサンプリング(nearest neighbor等)して高解像度に合わせる AI コード5行
- 3リサンプリング後のshape不一致(端数ピクセル)を明示的にハンドルする。パディングまたはトリムで揃える AI コード5行
Day5で体験: SCL(20m)を2倍リサンプリングすると、B04/B08(10m)とshapeが1ピクセルずれる → numpy配列のトリム/パディング処理が必要だった
SARの場合: スペックルフィルタ 体験済
- 1scipy.ndimage.uniform_filter でLeeフィルタを適用(窓サイズ7×7) AI コード5行
- 2フィルタ前後の画像を並べて、ノイズが除去されつつ地物の境界が保たれているか確認 人間 5分
Day2でLeeフィルタ適用 → F1が0.364→0.396に改善(8.8%向上)を確認済み
⑤ 解析する — 画像から知りたいことを引き出す
前処理を終えたデータから「森林が減ったか」「洪水が起きたか」を判定する。簡単な方法から順に試すのがセオリー。
L1: 計算式で判定する(最も簡単) 体験済
- 1目的に合うスペクトル指数を選ぶ。森林→NDVI、水域→NDWI、都市→NDBI、火災跡→NBR AIが推薦 → 人間が選択
- 2指数を計算する。例: NDVI = (B08 - B04) / (B08 + B04) AI コード3行
- 3閾値を決める。例: NDVI < 0.3 → 「森林ではない」。閾値は0.1刻みで変えながら精度を確認 AIコード生成 → 人間が判断
- 4結果を地図上に表示して目視確認 AI コード10行
コード全体
20-30行 計算: 数秒精度の目安(用途別)
分類(土地被覆): F1 = 0.4-0.7変化検出(森林減少等): F1 = 0.2-0.4
Day5実測: NDVI閾値法 vs Hansen → F1=0.31
L2: 既存AIモデルをそのまま使う 体験済
- 1HuggingFace / TorchGeo で目的に合う学習済みモデルを検索する AI 5分
- 2モデルをダウンロードしてロードする AI コード15行 待ち DL 1-5分
- 3前処理済み画像を入力形式に変換(リサイズ・正規化・チップ化)して推論実行 AI コード30行
- 4結果を可視化して精度確認 AIコード → 人間が判断
計算時間
CPU: 数分(画像数枚)GPU: 数十秒
注意点
学習条件(地域・季節)が自分のデータと合わないと精度が急落する。Day2で体験済み(F1=0.17)L2.5: 既存モデルを少量データで微調整する ★実務で最も多い 部分的
- 1L2の結果が精度不足の場合、対象地域の正解データを5-50枚用意する 人間 数時間〜数日
- 2既存モデルの最終層だけを対象データで再学習(Fine-tuning) AI コード50行
- 3GPU学習を実行 環境 待ち
- 4精度を再評価。L1/L2との比較表を作成 AI → 人間が判断
GPU学習時間の目安
T4(Colab無料): 1-3時間A100: 10-30分
CPU: 半日〜1日
精度改善の目安
5枚のGTで F1 +0.1-0.2 改善が一般的50枚あれば F1 +0.2-0.3 も可能
L3: ゼロからモデルを作る(GT収集が必要) 部分的
- 1正解データ(GT)を作る: 衛星画像を開き、「ここは森林」「ここは農地」と人間が1ピクセルずつ塗り分ける 人間
- 2数百〜数千枚のアノテーション。ツール: QGIS / Label Studio / Labelbox 人間 数週間〜数ヶ月
- 3画像を256×256のチップに分割し、地理的にtrain/val/testに分ける(ランダム分割は不可) AI コード30行
- 4U-Net等のモデルを選定して学習コードを生成 AI コード100行
- 5GPU学習を実行 環境 待ち
- 6精度が不足 → 手順1に戻ってGT追加 → 再学習(反復) 人間
GPU学習時間(100エポック)
T4: 2-4時間 / A100: 30分 / CPU: 2-3日Day2の実績
U-Net 20エポック CPU: 53分 → F1=0.24GPU+100エポックで F1>0.5 が見込まれる
手順2の「人間がピクセルを塗る作業」がプロジェクト全体の最大ボトルネック。AIでは代替できない。既存データセット(Global Forest Watch等)が使えるならここをスキップできる — だから「既存データセットがあるもので回す」戦略が有効。
⑥ 結果を検証して仕上げる
解析結果は「ピクセルの塗り絵」状態。これを使える形に仕上げ、精度を確認する。不十分なら⑤に戻る。
AOIクリッピング + 精度評価 体験済
- 1解析結果をAOI(コンセッション等)ポリゴンでクリップする。BBOXのまま面積計算すると3-12倍の過大推定になる AI コード10行(rasterize + mask)
- 2孤立ピクセル(1ピクセルだけ「森林減少」と出ている箇所)をモルフォロジー処理で除去 AI コード5行
- 3ピクセルの集まりをポリゴン(境界線で囲まれた区画)に変換。rasterio.features.shapes を使用 AI コード10行
- 4各ポリゴンの面積をヘクタール単位で計算 AI コード5行
- 5正解データ(Hansen GFW等)と比較してF1 / IoU / Precision / Recall / 面積誤差を計算。閾値を複数試して最適F1を求める AI コード30行
- 6混同マップ(TP/FP/FN/TN)を地図上に可視化して空間的なパターンを確認 AI コード20行
- 7精度が要件を満たすか判断。不足なら⑤に戻って手法変更 or GT追加 人間 議論
Day5実績: NDVI閾値法 vs Hansen GFW → 最適閾値-0.325でF1=0.31、Precision=27.9%、Recall=33.7%。検出3,953ha vs 実際3,272ha。面積は近いが位置の一致は3割程度 → L2へのエスカレーションが必要と判断
AOIクリッピングを忘れると面積が大幅に過大推定される。Day5ではBBOXのまま計算した初版で実際の3-12.5倍の面積を検出してしまった。コンセッション境界でrasterize maskをかけることで正しい面積に修正。
既知の正解データ(GT)ソースを活用する 体験済
GT収集は「数週間〜数ヶ月」のボトルネックだが、グローバルな既存データセットを使えばGT収集をスキップできるケースがある。
| GTソース | 種類 | 解像度 | 用途 |
|---|---|---|---|
| Hansen GFW | 年次森林減少ピクセルマップ(2001-2023) | 30m | 森林減少の精度検証・閾値最適化 |
| Trase | コンセッション別年次伐採面積 | コンセッション単位 | 面積レベルの妥当性検証 |
| JRC Global Surface Water | 水域変化マップ(1984-) | 30m | 洪水・水域変化の検証 |
| ESA WorldCover | 土地被覆分類(年次) | 10m | 土地利用分類の検証 |
| OpenStreetMap | 道路・建物・土地利用 | ベクター | 都市域の検証 |
「GTを自分で作る前に、既存のグローバルデータセットで代替できないか」を必ず検討する。Day5ではHansen GFW(無料・30m・年次)を使ってGT収集ゼロで精度評価を完了した。
⑦ 地図にする
解析結果を既存の地図(道路・建物・行政区画)と重ねて、実務的に意味のある地図にする。
解析結果 + 衛星写真 + 重ね合わせ地図 体験済
- 1foliumで地図を作成。OSM + 衛星写真(Esri)をベースマップに指定 AI コード10行
- 2RGB真カラー画像(B04/B03/B02)のBefore/Afterオーバーレイを作成。コントラスト調整(2-98パーセンタイル)+ ダウンサンプリングでPNG化 AI コード50行
- 3NDVI変化マップ、Hansen正解データ、混同マップ(TP/FP/FN/TN)をレイヤーとして重ねる AI コード30行
- 4解析結果パネル(精度指標、凡例、解釈)をHTML内に埋め込む AI コード80行
- 5コンセッション境界をGeoJSONレイヤーで重ねる AI コード10行
- 6地図を見て空間パターンを読み取る(「道路沿いに減少」「川沿いは安定」等) 人間
Day5実績: 7レイヤーのインタラクティブマップを生成(RGB Before/After + NDVI 2017/2019 + NDVI変化 + Hansen + 混同マップ + コンセッション境界)。レイヤー切替でBefore→Afterの伐採を視覚的に確認可能。
⑧ 届ける
誰に・どう届けるかで作るものが変わる。プロトタイプレベルなら実はどれも数時間で動く。
インタラクティブ地図(Streamlit + folium) 未体験
- 1Streamlitアプリを作成。サイドバーに日付選択・レイヤー選択UIを配置 AI コード30行
- 2⑦の地図をStreamlitに埋め込む AI コード10行
- 3streamlit run app.py でローカル起動して確認 AI 1分
従来
Webエンジニアがフロント+バック構築 → 2-8週間AI導入後
AIが Streamlit+folium コード生成 → プロトタイプ 1-2時間自動アラート(Slack通知) 未体験
- 1Slack Incoming Webhook URLを取得(Slack管理画面で設定) 人間 5分
- 2変化検出結果で閾値超え(例: 1ha以上の新規減少)があるかチェック AI コード5行
- 3閾値超えがあれば requests.post でSlackに送信。メッセージに面積・位置・サムネイルを含める AI コード15行
Slack通知は全部で20行、30分で動く。「数ヶ月」かかるのはSlack通知ではなく、その手前の⑤変化検出パイプラインと⑨の定期実行基盤の構築。
⑨ 運用する(継続監視の場合のみ)
一回だけの分析なら⑧で完了。毎月監視するなら③→⑧を自動で繰り返す仕組みが必要。
定期実行パイプライン 未体験
- 1③→④→⑤→⑥→⑦→⑧の処理をPythonスクリプト1本にまとめる AI コード200-300行
- 2cron(Linux)またはCloud Scheduler(GCP)で毎月実行を設定 AI コード5行
- 3実行ログを記録し、エラー時にSlack通知する仕組みを追加 AI コード20行
- 4四半期ごとにモデル精度を新しいGTで再検証する日程を決める 人間
並行: データ管理
全工程を通じて「何のデータで、何の処理をして、この結果を出したか」を記録する。半年後に再現できなくなることを防ぐ。
処理ログの自動記録 未体験
- 1各処理スクリプトの先頭で、入力ファイル・パラメータ・日時をJSONに書き出す AI コード10行(各スクリプトに追加)
- 2出力ファイルにSTACメタデータ(座標範囲・日付・処理バージョン)を付与 AI コード20行
次のアクション
✅ Round 1 完了: 森林減少で①〜⑦を1本通した(Day 5)
L1(NDVI閾値法)でPT TAIYOUNG ENGREEN HTI(中央カリマンタン)の2017→2019森林減少を検出。
Hansen GFW v1.11で検証し F1=0.31(Precision=28%, Recall=35%)を確認。
foliumインタラクティブ地図(RGB Before/After + 6レイヤー)を出力。
L1(NDVI閾値法)でPT TAIYOUNG ENGREEN HTI(中央カリマンタン)の2017→2019森林減少を検出。
Hansen GFW v1.11で検証し F1=0.31(Precision=28%, Recall=35%)を確認。
foliumインタラクティブ地図(RGB Before/After + 6レイヤー)を出力。
次のステップ
- L2 / L2.5 への昇格 — Random Forest(L2)または Prithvi微調整(L2.5)で精度向上を検証。F1=0.31→0.5以上を目標
- 横展開 — 他のコンセッション・他のユースケース(洪水、都市化)で同じ①〜⑦パイプラインを再利用
- ⑧ 届ける — Streamlit化やSlack通知で関係者にデリバリー
- ⑨ 運用する — 定期実行パイプライン構築(cron / Cloud Scheduler)